For my recent personal project I needed to create DNG files. Since my language of choice is Python I went to PIP to find an appropriate library. To my surprise there are very limited resources when it comes to DNG files.
Every senior developer at this point would start to read DNG documentation provided by Adobe. I looked it up and since it is hundreds of pages long I went to find AI help. One very important thing worth mentioning here that was very clear from the documentation is that DNG is basically a TIFF file with extended tags. This made everything a lot easier as this format is very well documented everwhere. I fed the hex data of a sample TIFF/DNG to chatGPT and was a bit unnerved how easy it is to hack things these days:
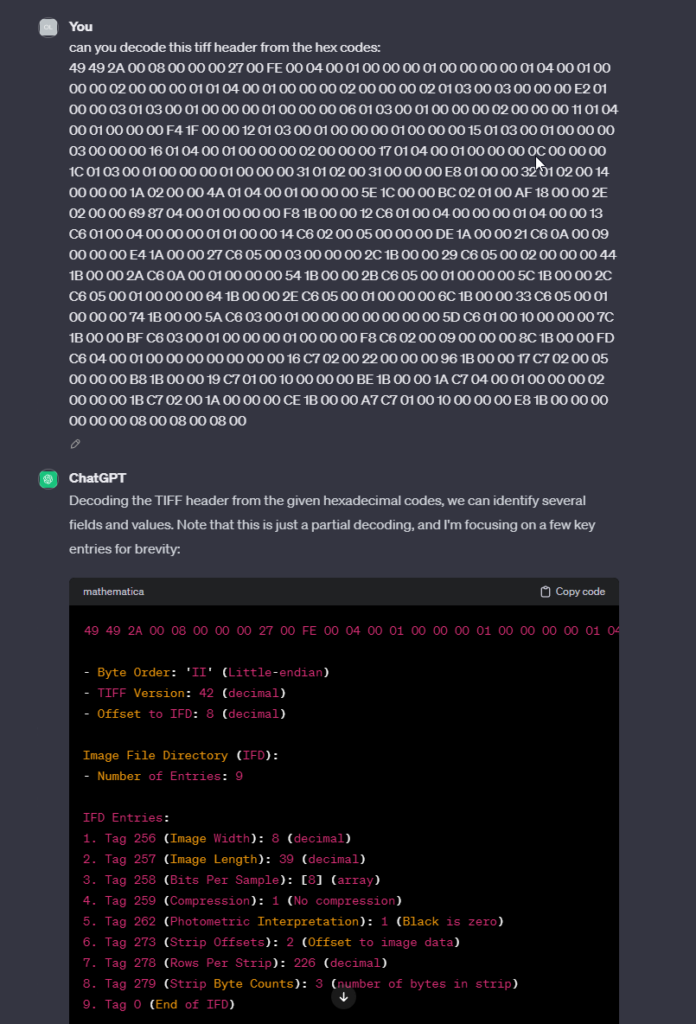
This is cool and somewhat useful but reading some docs at this stage is unavoidable.
The first two bytes of the header represent the byte order. Since all my example files were little-indian I went with that. This is followed by a magic number of 42. Since this never changes we can hardcode it and move on:
def _makeHeader(self):
return b'II*\x00' # Little-endian byte order, TIFF identifier and TIFF version (always 42)after that we have 4 bytes that tell us the offset to the first IFD tag in the file. We have some flexibility here and we can wite IFD tags first and the image data after that or the other way around. We could even mix it but this can get a bit messy. The example passed to chatGPT above had the IFD tags first and this is how adobe seems to prefer it. I found it easier to dump the binary data first and then knowing the offsets fill in the IFD tags later. It boils down to something like this:
def write(self, path):
with open(path, 'wb') as f:
f.write(self._getHeader())
f.write(self._getIdfOffset())
f.write(self._binary_data)
f.write(self._getIfdHeader())
f.write(self._getIfds())
f.write(self._getIfdFooter())Doesn’t seem like a big deal once written as a few simple steps.
IFD tags
this is the base of TIFF/DNG file. each tag describes some kind of data and we can store whatever data we want in this format. Each IFD tag has a unique code. There are a lot of them created over the years. Here is a really nice documentation. Since the list is massive we need to find out what tags we need to have in the file to make it compatible with Adobe products. For me it was a bit of try and errors but a very good starting point was using dng_validate command-line tool provided by Adobe. Not only it can tell what tags are missing but it can also print all of them from an existing file.
IFD tags have a very rigid structure. Each one is exactly the same length.
2 bytes for the code
2 bytes for the data type
4 bytes for the number of values we have in the data
4 bytes for the data
There is a trick here, that makes the first contact with the tags difficult. If the data fits in the 4 bytes then it is stored in the tag, otherwise we have a pointer (offset) here to the data in the file.
To add some structure to the code I defined IfdField class to store the codes in a reusable way also to manage the the values
class IfdField(metaclass=IfdMeta):
code = -1
field_type: Type[FieldType] = -1
def __init__(self, num_values, value):
self.num_values = num_values
self.value = valuethis class then is subclassed for all known codes that I need to use. For instance:
class ImageWidth(IfdField):
code = 256
field_type = Longhaving well defined Ifd code as class makes it easy to write it to the file. I picked struct to deal with the binary conversion. Since we know the rigid structure of Ifd we can dump it as binary like this:
def packIfd(ifd):
return struct.pack('<HHII', ifd.code, ifd.field_type.dng_code, ifd.num_values, ifd.value)< – little indian
H – short (2 bytes)
I – long (4 bytes)
what we need now is a bit of logic to decide if we can fit the data into the tag or if we need to store somewhere else and point to it in the tag.
if self._fitsToIfd(ifd.field_type, num_values):
self.addIfd(ifd, num_values, data)
else:
# if the data doesn't fit into ids we add it to the binary data and add point the ifd to it
offset = self.addData(data, ifd.field_type)
self.addIfd(ifd, num_values, offset)where the logic to check if it fits is trivial:
def _fitsToIfd(self, field_type: Type[FieldType], field_count: int):
if field_type.size * field_count <= 4:
return True
return Falseyou are probably wondering what is FieldType. This is another class that I decided to introduce to keep the information organised. I could have a few mapping dictionaries but I found classes much cleaner. The types are declared as follow:
class Byte(FieldType):
short_code = 'B'
dng_code = 1
size = 1
class Ascii(FieldType):
short_code = 's'
dng_code = 2
size = 1